13 The EdSurvey suggestWeights Function
Last edited: November 2023
Suggested Citation
Huo, H. The EdSurvey suggestWeights Function. In Bailey, P. and Zhang, T. (eds.), Analyzing NCES Data Using EdSurvey: A User’s Guide.
13.1 Introduction
The suggestWeights function in EdSurvey allows you to specify the list of variables you intend to use in an analysis and suggests sample weights that may be appropriate for the analysis. Final weight variable selection, however, is up to the user and should be based on a detailed understanding of the available analytic weights. Currently, the suggestWeights function has been implemented for the Early Childhood Longitudinal Study, Kindergarten Class of 2010–11 (ECLS-K:2011), sponsored by the National Center for Education Statistics (NCES) within the Institute of Education Sciences of the U.S. Department of Education.
Sampling weights designed for use with data from a complex sample survey, such as the NCES longitudinal studies, serve two primary purposes. When used in analyses, the main sampling weight weights the sample size up to the population total of interest. For NCES sample surveys, weighting produces national-level estimates. Also, the main sampling weight adjusts for differential nonresponse patterns that can lead to bias in the estimates. The ECLS-K: 2011 Data File User’s Manuals (Tourangeau, 2015a, 2015b, 2018a, 2018b, 2017, 2019) indicate that if people with certain characteristics are systematically less likely than others to respond to a survey, the collected data may not accurately reflect the characteristics and experiences of the nonrespondents, which can lead to bias. To adjust for this, respondents are assigned weights that, when applied, result in respondents representing their own characteristics and experiences as well as those of nonrespondents with similar attributes (Tourangeau, 2015a, 2015b, 2018a, 2018b, 2017, 2019).
For longitudinal studies (e.g., ECLS-K: 2011), a sample weight could be produced for use with data from every component of the study (e.g., student questionnaires, parent surveys, student assessment component, transcript component) at every round of data collection and for every combination of components and rounds. However, creating all the possible weights for a study with as many components as the NCES longitudinal studies would be impractical. Therefore, there may not be a weight that adjusts for nonresponse to the exact number of components and rounds included in an analysis.
When no weight corresponds exactly to the combination of components included in the analysis, researchers might prefer to use a weight that adjusts for nonresponse to more components than those in the analysis. As discussed in the ECLS-K:2011 User’s Manuals (Tourangeau, 2015a, 2015b, 2018a, 2018b, 2017, 2019), general guidance for weight selection is that (a) although a weight that includes nonresponse adjustment for more components than those in the analysis results in a smaller analytic sample, it helps adjust for the potential differential nonresponse associated with the components; and (b) if a weight with nonresponse adjustments for fewer components is used, then examine missing data for potential bias.
Please refer to the study-specific documentation for more comprehensive information about the analytic weights available for each study and the analysis for when each weight is best suited. For more information about ECLS-K:2011 data and data documentation, please visit the ECLS-K Data Products page.
13.2 Using the suggestWeights Function to Determine the Weight
As discussed earlier, it is important to weight the data in your analyses using an appropriate sampling weight. However, with more than 100 base weights available in the ECLS-K:2011 data, you may find it difficult to choose. The suggestWeights function allows you to specify the variables you intend to use in an analysis, suggests a list of sample weights that may be appropriate for the analysis, and provides you with a head start to make informed decisions about weight selection.
To use the suggestWeights function, the first step is to attach the EdSurvey package and load the ECLS-K:2011 data. For more information, see 10. Longitudinal Datasets. The following code attaches the EdSurvey package and reads in the ECLS-K:2011 Kindergarten–Fifth Grade public-use data file with the parameters specified as follows:
library(EdSurvey)
eclsk11 <- readECLS_K2011(path = paste0(edsurveyHome,"ECLS_K/2011"),
filename = "childK5p.dat",
layoutFilename = "ECLSK2011_K5PUF.sps",
verbose = FALSE)Next, provide the variable(s) intended to use for the analysis. The suggestWeights function can suggest weight(s) from the variable(s) provided. If you create new variables or rename variables, you will need to enter the source variables used for creating these variables in suggestWeights because the function uses information from the original variable name to determine the component and the round before it returns suggested weight(s).
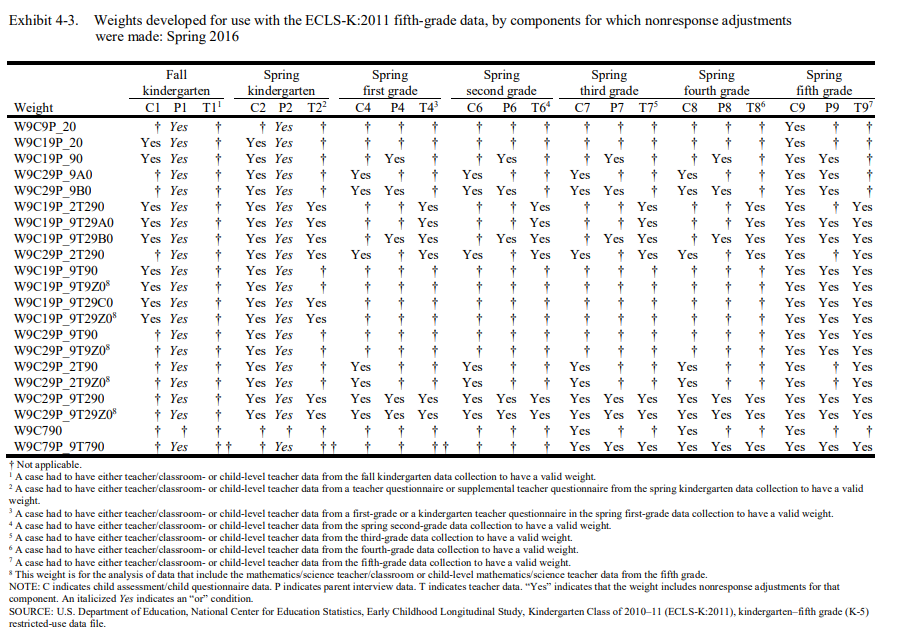
The following example demonstrates an analysis using child assessment data from spring third grade. The weight w9c790 would be suggested once the variables are specified. As shown in the ECLS-K:2011 User’s Manual (Tourangeau, 2019), the weight w9c790 is “child base weight adjusted for nonresponse associated with child assessment/child questionnaire data from spring third grade, spring fourth grade, and spring fifth grade (C7C8C9).”
suggestWeights(varnames = c("x7mscalk5", "x8mscalk5", "x9mscalk5"),
eclsk11)
#> Based on your specification, below is/are the suggested weight(s). But please double
#> check the manual to be sure to use the best weight for your analysis.
#> [1] "w9c790"The weight returned by the suggestWeights function can be used in EdSurvey’s analytic functions for further analysis. For the ECLS-K:2011 study, EdSurvey uses all corresponding replicate weights and estimates the variance of the coefficients with the Jackknife method. Additional information on variance estimation of ECLS-K:2011 variables is available in 10. Longitudinal Datasets.
To print out additional information on weight suggestion, such as the number of cases with a valid main sampling weight, weight description, variables(s) used in weight suggestions and variable(s) that the user has specified but are not used in the weight suggestion, use the verbose = TRUE option:
suggestWeights(varnames = c("x1mscalk5", "x2mscalk5", "x3mscalk5",
"x4mscalk5", "x5mscalk5", "x6mscalk5", "x7mscalk5", "x8mscalk5"),
eclsk11, verbose = TRUE)
#> Based on your specification, below is/are the suggested weight(s). But please double
#> check the manual to be sure to use the best weight for your analysis.
#> The following weight is suggested:
#> Weight: w8cf8p_80
#> Number of cases: 2,354
#> Description: Child base weight adjusted for nonresponse associated with child
#> assessment/child questionnaire data from all eight rounds from kindergarten
#> through fourth grade, as well as parent data from fall kindergarten or spring
#> kindergarten, and parent data from all rounds from fall first grade through
#> spring fourth grade. (C1C2C3C4C5C6C7C8)(P1_P2)(P3P4P5P6P7P8)
#>
#>
#> Weight selection based on the inclusion of the following variables:
#> varnames source
#> 1 x1mscalk5 Fall 2010 composite/derived variables
#> 2 x2mscalk5 Spring 2011 composite/derived variables
#> 3 x3mscalk5 Fall 2011 composite/derived variables
#> 4 x4mscalk5 Spring 2012 composite/derived variables
#> 5 x5mscalk5 Fall 2012 composite/derived variables
#> 6 x6mscalk5 Spring 2013 composite/derived variables
#> 7 x7mscalk5 Spring 2014 composite/derived variables
#> 8 x8mscalk5 Spring 2015 composite/derived variables
#> [1] "w8cf8p_80"Often, there are trade-offs for using one weight versus another among the possible weights, and you may want to compare using different weights before making a final decision. To display all applicable weights that adjust for nonresponse to more components than what are included in the analysis, which typically are more conservative with smaller sample size, use the showAllWeightSuggestions = TRUE option:
suggestWeights(varnames = c("x1mscalk5", "x2mscalk5", "x3mscalk5",
"x4mscalk5", "x5mscalk5", "x6mscalk5", "x7mscalk5", "x8mscalk5"),
eclsk11, showAllWeightSuggestions = TRUE, verbose = TRUE)
#> Based on your specification, below is/are the suggested weight(s). But please double
#> check the manual to be sure to use the best weight for your analysis.
#> The following weights are suggested:
#> Weight: w8cf8p_80
#> Number of cases: 2,354
#> Description: Child base weight adjusted for nonresponse associated with child
#> assessment/child questionnaire data from all eight rounds from kindergarten
#> through fourth grade, as well as parent data from fall kindergarten or spring
#> kindergarten, and parent data from all rounds from fall first grade through
#> spring fourth grade. (C1C2C3C4C5C6C7C8)(P1_P2)(P3P4P5P6P7P8)
#>
#>
#> Weight: w8cf8p_2t180
#> Number of cases: 2,715
#> Description: Child base weight adjusted for nonresponse associated with child
#> assessment/child questionnaire data from all eight rounds from kindergarten
#> through fourth grade, as well as parent data from fall kindergarten or spring
#> kindergarten, and teacher data from fall and spring kindergarten, fall and
#> spring first grade, fall and spring second grade, spring third grade, and spring
#> fourth grade (C1C2C3C4C5C6C7C8)(P1_P2)(T1T2T3T4T5T6T7T8) Note: This weight was
#> created with nonresponse adjustments for the reading teacher only. There is no
#> similar weight with nonresponse adjustments for the mathematics or science
#> teacher.
#>
#>
#> Weight selection based on the inclusion of the following variables:
#> varnames source
#> 1 x1mscalk5 Fall 2010 composite/derived variables
#> 2 x2mscalk5 Spring 2011 composite/derived variables
#> 3 x3mscalk5 Fall 2011 composite/derived variables
#> 4 x4mscalk5 Spring 2012 composite/derived variables
#> 5 x5mscalk5 Fall 2012 composite/derived variables
#> 6 x6mscalk5 Spring 2013 composite/derived variables
#> 7 x7mscalk5 Spring 2014 composite/derived variables
#> 8 x8mscalk5 Spring 2015 composite/derived variables
#> [1] "w8cf8p_80" "w8cf8p_2t180"If the function returns the message “cannot determine weights for variables provided” or returns weights that are too conservative, try to remove some variable(s) from the variable list that have the least amount of nonresponse or that are of the least analytical interest. This is especially helpful in the exploratory data analysis stage.
13.3 General Considerations When Selecting Weights
Within a research study, we recommend using the same main sample weight for all analyses so that the underlying sample used to produce the estimates is the same across analyses. Therefore, the analytic weight should be selected based on all variables included in all key research questions. The set of individuals with a valid weight then becomes the analytic sample for all analyses within the study. You may want to consider removing some variables if no weights or too conservative weights are returned. In addition, missing data should be examined if the weights returned adjust for nonresponse to fewer components than what’s included in the analysis.
13.4 Inside suggestWeights
The suggestWeights function determines the component and round of variables by the prefixes in the variable names. For example, the variable p8games, which corresponds to the question about how often the parent respondent or any other family members play games or do puzzles with the child in a typical week in the spring 2015 parent interview, starts with “P8,” which stands for the “parent” component and round “8” (spring 4th grade). If new variables are created or variables are renamed, you will need to enter the source variables used for creating these variables in suggestWeights because the prefixes in the original variable name contain information on the component and round for the function to work properly. The ECLS-K:2011 User’s Manuals provide an exhaustive list of prefixes in Exhibit 7-1 in the manuals (Tourangeau, 2015a, 2015b, 2018a, 2018b, 2017, 2019).
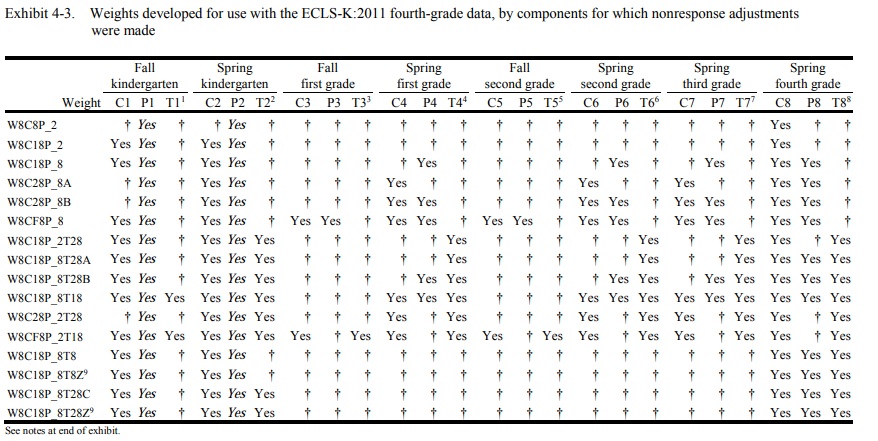
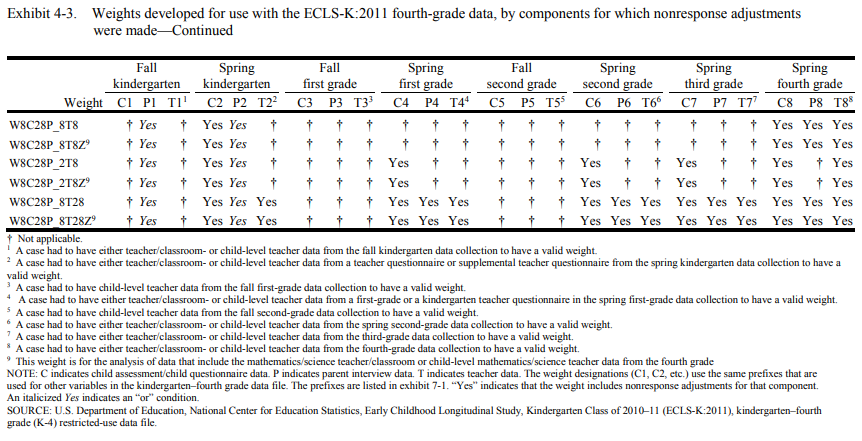
For most individual pairs of a specific component and a given round, one or more weights will adjust for nonresponse to those elements. For example, weights such as “w8c18p_80, w8c28p_8a0, w8c28p_8b0, w8cf8p_80…” all adjust for nonresponse to the parent component from round 8 (variables that start with “P8”), in varying combinations of other components. The ECLS-K:2011 User’s Manuals (Tourangeau, 2015a, 2015b, 2018a, 2018b, 2017, 2019) and the appendix of this vignette summarize this adjustment.
For each input variable, the algorithm will generate a list of all possible weights. An intersection of these lists will provide the common set of weights that apply to all input variables that will be returned by the function. In case there is no intersection, an error message “no weight suggestions for the following variables:…” will be raised. Consider consulting the ECLS-K:2011 User’s Manuals (Tourangeau, 2015a, 2015b, 2018a, 2018b, 2017, 2019) for complete descriptions of the analytic weights.
If there are weights that adjust for nonresponse to the exact combination of components included in a given analysis, suggestWeights would return these weight(s). If there are multiple weights adjusting for nonresponse to these components, the algorithm would rank possible weights using the following rule: On top of the components included in the analysis, the weight that adjusts for nonresponse to the smallest number of any additional components will be ranked the top recommendation. Why? Although all the weights in the returned list will adjust for the potential differential nonresponse associated with the components, choosing the weight that includes nonresponse adjustments for more components than you are using in your analysis would result in a smaller analytic sample. For example, W8C8P_2 adjusts for nonresponse to three components (i.e., P1, P2, and C8), and W8C18P_2 adjusts for nonresponse to five components (i.e., C1, P1, C2, P2, C8). If only “C8” variables are used in the analysis, W8C8P_2 will be prioritized because it includes not only nonresponse adjustments for the component included in the analysis but also fewer components not included in the analysis. Multiple weights would be suggested and returned if there is a tie.
Lastly, the suggestWeights function limits the weight(s) returned so that the round for which the weight includes nonresponse adjustment will not exceed the highest round in the input variables. For example, although both weights W1_2P0 and W9C9P_20 can adjust for nonresponse to the parent interview for either fall kindergarten or spring kindergarten, the latter weight would be excluded from the weights suggested for an analysis that involves parent data from the kindergarten year only. Why? The weight W9C9P_20 also adjusts for nonresponse to the child component from round 9, which would not be found in the input variables for this particular analysis.
13.5 Limitations
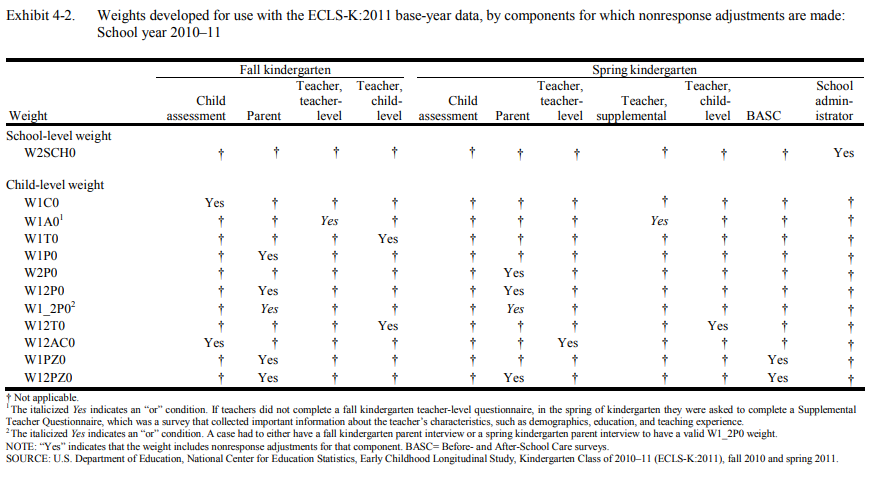
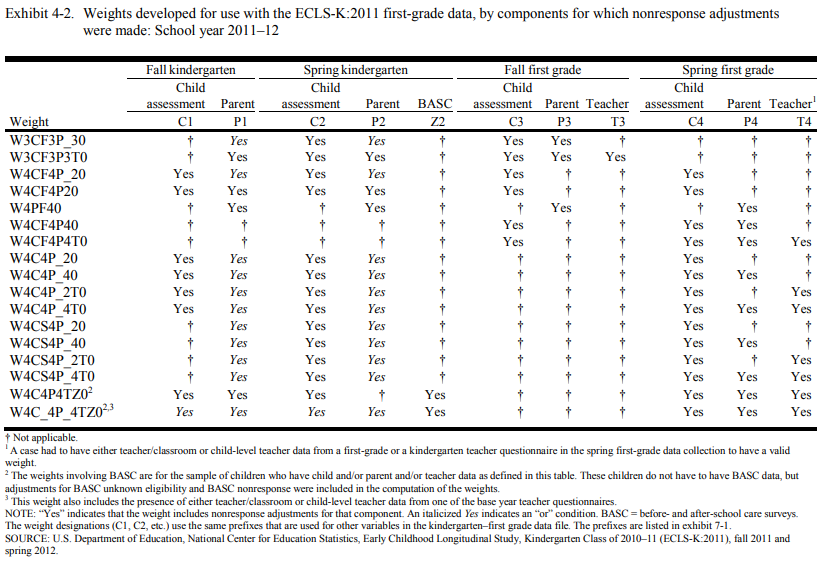
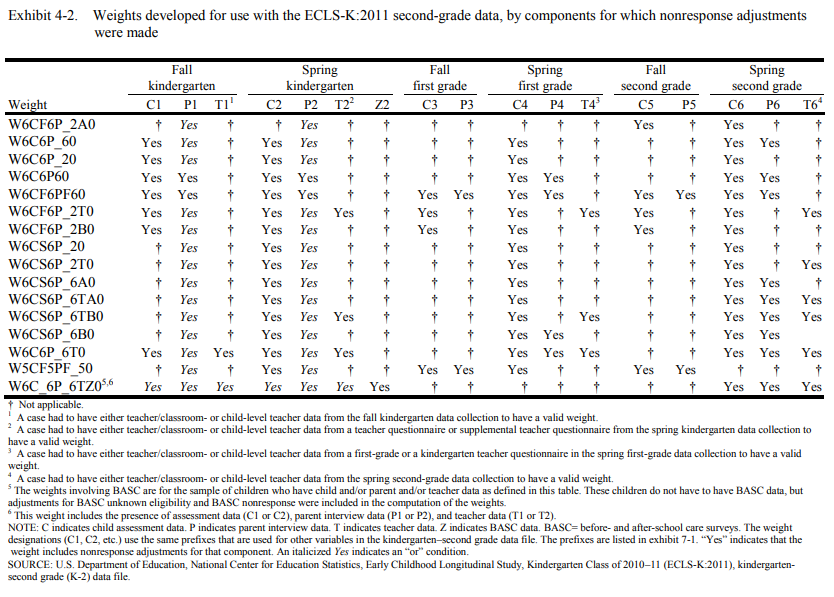
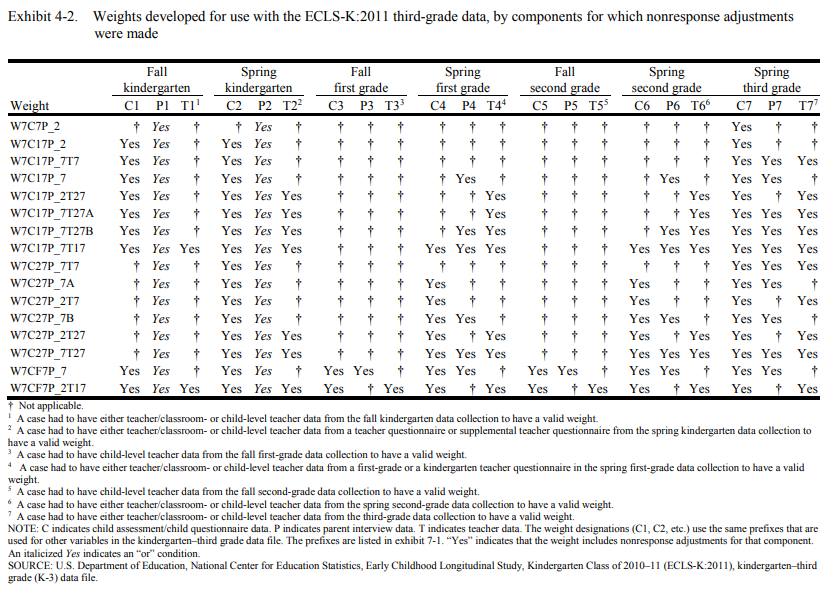
First, the suggestWeights function does not distinguish the “or” condition from the “and” condition among components. This applies to weights with italicized Yes in the appendix. For example, you may see both weights W12P0 and W1_2P0 returned for a given analysis but it is possible that only one weight is applicable for the analysis because the former weight adjusts for nonresponse to the parent component in both the fall “and” spring kindergarten collections while the latter adjusts for nonresponse to the parent component in fall “or” spring kindergarten collection. Consider referring to the table note of Exhibit 4-2 (Tourangeau, 2015a, 2015b, 2018a, 2017) or Exhibit 4-3 (Tourangeau, 2018b, 2019) in the ECLS-K:2011 User’s Manuals for more information about the “or” and “and” conditions.
Second, the classification of round-specific composite variables (i.e., variables with prefix X#) is based on their variable description. For example, the component of all round-specific composite variables with “teacher report” in their description would be classified as “teacher,” and the component of all round-specific composite variables with “parent report” in their description would be classified as “parent.” The suggestWeights function may not yield appropriate weights if the input variables include a composite variable that is created using multiple components. For example, the race/ethnicity composite variable x_raceth_r draws from either the parent-reported data about the child’s race or the field management system (FMS), with FMS data used only if parent responses about the child’s race were missing. If this variable is included in the desired analysis, it will be excluded from the weight selection process. Please review the weights returned, if any, with more guidance from the ECLS-K:2011 User’s Manuals (Tourangeau, 2015a, 2015b, 2018a, 2018b, 2017, 2019).
Third, the suggestWeights function is intended for single-level analysis but not multilevel modeling (MLM). Consider referencing to the ECLS-K:2011 User’s Manuals (Tourangeau, 2015a, 2015b, 2018a, 2018b, 2017, 2019) for more guidance on conducting MLM analyses using ECLS-K:2011 data.
13.6 APPENDIX
The ECLS-K:2011 is a longitudinal data set weighted to compensate for unequal probabilities of selection at each sampling stage and adjust for the effects of nonresponse to various components on generated estimates, including parent interviews, teacher questionnaires, before- and after-school care provider questionnaires (if applicable), school administrator questionnaire, child questionnaires, and direct child assessment (Mulligan, 2018).
The following exhibits (Tourangeau, 2015a, 2015b, 2018a, 2018b, 2017, 2019) were developed to further assist researchers in deciding which weight to use for analyses. The components for which nonresponse adjustments are made for each weight are noted with a “Yes.” The most appropriate weight for a given analysis would have a “Yes” for every component used in the analysis and only those components.